使用csharp简单实现的bp神经网络
在此之前最好先安装 Collapsenav.Net.Tool nuget包
bpnn是反向传播神经网络(Back Propagation Neural Network)算法, 是一种监督式学习的多层前馈神经网络, 可以说是现代神经网络的鼻祖和奠基者, 提出了反向传播算法用于更新连接权重
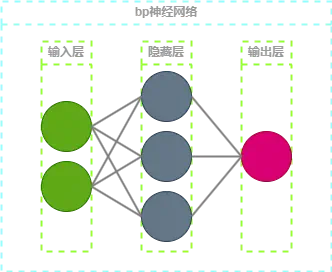
bp神经网络的结构如上图所示, 包括输入层, 隐藏层和输出层
每个圆形都是一个神经元(Neuron), 每层神经元之间通过突触(Synapse)连接
神经元(Neuron)

一般来说一个神经元的计算需要由以上组成部分参与
其结构用代码表示大概就是下面这样
public class Neuron
{
/// <summary>
/// 神经元本身的输出值
/// </summary>
public double Value { get; set; }
/// <summary>
/// 激活函数
/// </summary>
public ActivationFunction ActivationFunction { get; set; }
/// <summary>
/// 偏置
/// </summary>
public double Bias { get; set; }
/// <summary>
/// 输入连接
/// </summary>
public List<Synapse> Inputs { get; set; }
/// <summary>
/// 输出连接
/// </summary>
public List<Synapse> Outputs { get; set; }
}
Inputs 和 Outputs 分别对应输入输出的突触结构, 输入是与上一层所有神经元的连接, 输出是与下一层所有神经元的连接
突触(Synapse)
然后来看一下突触(Synapse)的结构

突触的结构相比神经元来说就非常简单了, 只有前后两个神经元和这条连接的对应权重, 毕竟突触的作用也就是连接前后两个神经元
public class Synapse
{
/// <summary>
/// 输入端
/// </summary>
public Neuron Input { get; set; }
/// <summary>
/// 输出端
/// </summary>
public Neuron Output { get; set; }
/// <summary>
/// 权重
/// </summary>
public double Weight { get; set; }
}
激活函数(ActivationFunction)
前几层的神经元在计算时需要过一次非线性的激活函数, 使其可以处理现实中的复杂问题
如果使用的是线性激活函数, 不管网络有多少层, 最终的输出还是一个线性的结果, 可能只适用于拟合直线之类的简单问题
而实际中我们需要通过神经网络处理的大多都是一些非线性的复杂问题, 因此需要引入非线性的激活函数来提高神经网络的表达能力
虽然有 sigmoid 这样的经典激活函数, 但这边还是用更加简单并且计算量更少的 Relu 作为演示, 方便代码的编写和理解

/// <summary>
/// 激活函数
/// </summary>
public interface IActivationFunction
{
/// <summary>
/// 前向
/// </summary>
double Forward(double input);
}
public class ReLu : IActivationFunction
{
public double Forward(double input) => input > 0 ? input : 0;
public static ReLu Instance = new ReLu();
}
前向传播(Forward)计算
神经元接受上一层神经元的输出加权求和, 然后通过激活函数和偏置之后计算出自己的输出, 提供给下一层
因此我在神经元中定义一个 GetValue 方法用于计算自己的输出
public class Neuron
{
public double Value { get; set; }
/// <summary>
/// 激活函数(Relu)
/// </summary>
public ActivationFunction ActivationFunction { get; set; }
public double Bias { get; set; }
public List<Synapse> Inputs { get; set; }
public List<Synapse> Outputs { get; set; }
public double GetValue()
{
// 如果是输入层的神经元, 则直接返回输入值
if (Inputs.NotEmpty())
Value = ActivationFunction.Forward(Inputs.Sum(synapse => synapse.Weight * synapse.Input.GetValue()) + Bias);
return Value;
}
}
为了更加符合神经网络的定义, 下面再附上 Layer 和 Network 结构的简单定义
public class Layer : IEnumerable<Neuron>
{
/// <summary>
/// 上一层
/// </summary>
public Layer? Previous { get; set; }
/// <summary>
/// 下一层
/// </summary>
public Layer? Next { get; set; }
/// <summary>
/// 本层的神经元
/// </summary>
public Neuron[] Neurons { get; private set; }
public IEnumerator<Neuron> GetEnumerator()
{
return ((IEnumerable<Neuron>)Neurons).GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return Neurons.GetEnumerator();
}
}
public class NetWork
{
public List<Layer> Layers { get; set; }
/// <summary>
/// 输入
/// </summary>
public Layer Input => Layers.First();
/// <summary>
/// 输出层
/// </summary>
public Layer Output => Layers.Last();
}
Layer 只有一个神经元集合, Network 只有一个 层 的集合
在设置好神经网络 Input 层神经元的 Value 后, 调用神经网络 Output 层每个神经元的 GetValue 即可获得整个网络的输出
这个过程被称为 前向传播(Forward), 可以在 Network 中实现该方法
public class NetWork
{
public List<Layer> Layers { get; set; }
/// <summary>
/// 输入
/// </summary>
public Layer Input => Layers.First();
/// <summary>
/// 输出层
/// </summary>
public Layer Output => Layers.Last();
public double[] Forward(double[] inputs)
{
// 为输入层的神经元复制
Input.SelectWithIndex().ForEach(i => i.value.Value = inputs[i.index]);
// 调用输出层的GetValue方法, 计算输出层的神经元的输出值
return Output.Select(i => i.GetValue()).ToArray();
}
}
Forward 接收一组输入值, 前向传播计算完成之后返回最后一层的输出
反向传播
以上的内容是神经网络的前向传播, 接下来介绍下最重要的反向传播(Backward)
反向传播(Backward)是神经网络中一个非常重要的概念, 虽然网络可以通过前向传播计算输出, 但是其中的权重等参数都是随机的, 几乎不可能正好随机出一组可以拟合数据集的权重
因此我们需要在输出之后计算输出值与正确值的误差, 然后将这个误差一层一层反向传播回去, 根据这个误差一点一点调整权重
所以第一步就是算出误差, 为了简化计算, 我们可以直接使用最简单的相减之后的差值作为误差
public class Neuron
{
public double Value { get; set; }
public double GetError(double target) => target - Value;
}
public class NetWork
{
public List<Layer> Layers { get; set; }
public Layer Input => Layers.First();
public Layer Output => Layers.Last();
public double GetError(double[] target) => Output.SelectWithIndex().Sum(i => i.value.GetError(target[i.index]));
public double[] Forward(double[] inputs)
{
// 为输入层的神经元复制
Input.SelectWithIndex().ForEach(i => i.value.Value = inputs[i.index]);
// 调用输出层的GetValue方法, 计算输出层的神经元的输出值
return Output.Select(i => i.GetValue()).ToArray();
}
}
当网络经过 Forward 计算出每个神经元的 Value 之后, 将正确值输入 GetError 可计算出简单的误差值
// 使用输入进行前向传播计算
netWork.Forward(new double[] { 1, 2, 3 });
// 然后传入实际值计算出误差
netWork.GetError(new double[] { 23 });
当完成误�差计算之后, 我们需要做的就是想办法将这个误差从输出层一层一层反向传播回去, 并且在传播过程中同步更新神经元的偏置(Bias)和突触的权重(Weight)
所以之后我们需要计算的就是偏置和权重应该有的 偏移量, 这两个值都是浮点数, 要么变大要么变小, 难点在于确定向什么方向偏移
在这种情况下我们可以引入梯度(Gradient)这个东西, 偏置和权重可以根据梯度的方向进行调整
从定义上来讲, 梯度是损失函数在某个点的方向导数, 形象一点的就如下所示

从表现上来看就是函数上某个点的切线, 在实际问题中的函数大多不会是这么简单的
一般而言计算梯度时需要带入激活函数的偏导数进行计算, 之前选择Relu的一个原因就是其偏导数非常容易计算, 大于0时为1, 小于0时为0
public class ReLu : IActivationFunction
{
public double Forward(double input) => input > 0 ? input : 0;
public double Back(double input) => input >= 0 ? 1 : 0;
public static ReLu Instance = new ReLu();
}
由此添加一个 GetGradient 用于获取梯度
public class Neuron
{
public double Value { get; set; }
/// <summary>
/// 激活函数(Relu)
/// </summary>
public IActivationFunction ActivationFunction { get; set; }
public List<Synapse> Inputs { get; set; }
public List<Synapse> Outputs { get; set; }
/// <summary>
/// 梯度
/// </summary>
public double Gradient { get; set; }
public double GetError(double target) => target - Value;
public double GetGradient(double? target = null)
{
// 最后一层直接计算
if (target.HasValue)
Gradient = GetError(target.Value) * ActivationFunction.Back(Value);
// 如果存在输出神经元, 该神经元的梯度为后一层的梯度加权求和乘以偏导
if (Outputs.NotEmpty())
Gradient = Outputs.Sum(i => i.Output.Gradient * i.Weight) * ActivationFunction.Back(Value);
// 如果存在输入神经元, 则计算前一层的梯度
if (Inputs.NotEmpty())
Inputs.ForEach(i => i.Input.GetGradient());
return Gradient;
}
}
最后一层输出层根据实际值先计算出误差, 然后用误差进行计算
除此之外的其他层使用后一层的梯度乘以权重求和之后进行计算, 以此实现梯度从后向前反向传播
计算出所有神经元的梯度之后就可以着手更新偏置和权重了
在此需要引入 学习率(learning rate) 的概念
梯度代表参数变化的方向, 学习率则代表了每一次的步长
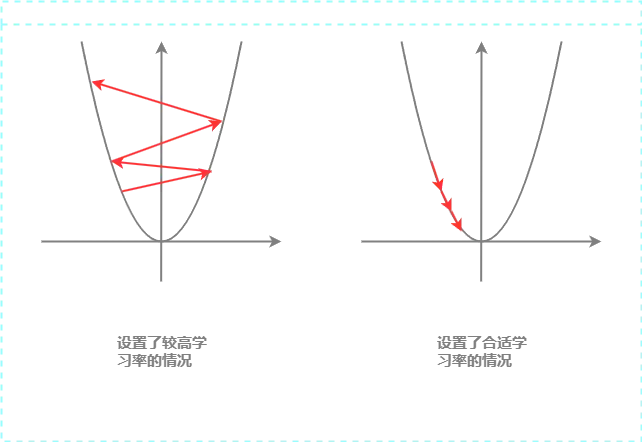
左图是学习率设大了的情况, 每次步子长了, 可能会导致梯度越来越大
如果设置了合适的学习率, 每次迈出的步子不大不小, 梯度会渐渐下降到相对较低的值
有了学习率和梯度, 相乘之后可以获得一个 权重变化量, 偏置和权重的更新就依据这个 权重变化量 进行变化
public class Neuron
{
public double Bias { get; set; }
public List<Synapse> Inputs { get; set; }
/// <summary>
/// 梯度
/// </summary>
public double Gradient { get; set; }
/// <summary>
/// 更新权重
/// </summary>
/// <param name="lr">学习率</param>
public void UpdateWeight(double lr)
{
// 计算权重变化量
var BiasDelta = lr * Gradient;
// 调整神经元的偏置
Bias += BiasDelta;
foreach (var synapse in Inputs)
// 更新突触权重
synapse.Weight += BiasDelta * synapse.Input.Value;
}
}
以上就是一个非常简单的权重更新算法
然后我们需要在 Network 中将以上内容组合起来, 通过实际值先计算梯度, 然后反向传播更新偏置和权重
public class NetWork
{
public List<Layer> Layers { get; set; }
/// <summary>
/// 输出层
/// </summary>
public Layer Output => Layers.Last();
public void Back(double[] target, double lr)
{
// 计算所有神经元的梯度, GetGradient 内部有递归处理
Output.SelectWithIndex().ForEach(kv => kv.value.GetGradient(target[kv.index]));
// 先将网络反过来
Layers.Reverse();
// 然后从后往前一层一层更新偏置和权重
Layers.ForEach(i => i.ForEach(ii => ii.UpdateWeight(lr)));
// 更新完成之后再度翻转, 使得网络恢复原状
Layers.Reverse();
}
}
训练时的代码类似下面这样
// 使用输入进行前向传播计算
netWork.Forward(new double[] { 1, 2, 3 });
// 然后传入实际值计算出误差
var error = netWork.GetError(new double[] { 23 });
// 反向传播更新权重
netWork.Back(new double[] { 23 });
完整代码
除了下面的代码, 也可以看看现成的仓库
- Program.cs
- Neuron.cs
- Synapse.cs
- IActivationFunction.cs
- Relu.cs
- Layer.cs
- Network.cs
这里使用了Kaggle上的数据集 学生表现
如果打不开 kaggle, 可以点击 下载文件
数据大致如下所示
| Hours Studied | Previous Scores | Extracurricular Activities | Sleep Hours | Sample Question Papers Practiced | Performance Index |
|---|---|---|---|---|---|
| 7 | 99 | Yes | 9 | 1 | 91 |
| 4 | 82 | No | 4 | 2 | 65 |
| 8 | 51 | Yes | 7 | 2 | 45 |
| 5 | 52 | Yes | 5 | 2 | 36 |
| 7 | 75 | No | 8 | 5 | 66 |
以下是一个简单的训练及验证的代码, 仅供参考
using Collapsenav.Net.Tool;
using bpnn_csharp;
IEnumerable<StudentPreference> datas = // 随便用什么办法读取数据, 保证格式没错就行 ;
// 划分训练集和测试集, 70%训练集,30%测试集
var rate = 0.7;
var train = datas.Take((int)(datas.Count() * rate)).ToList();
var test = datas.Skip(train.Count()).ToList();
// 一些超参设置
// 学习率
var lr = 1e-8;
// 最大迭代次数
var maxepoch = 50000;
// 目标误差
var targetError = 1e-3;
// 随机数种子
var seed = 0;
// 减少运算量, 每次只取十分之一进行计算(实际上没啥用,只是为了节省时间)
var count = train.Count / 10;
// 构建网络并且设置随机种子
NetWork model = new NetWork();
model.AddLayer(5, ReLu.Instance)
.AddLayer(6, ReLu.Instance)
.AddLayer(1, Linear.Instance)
.SetRandSeed(seed);
// 开始训练
Console.WriteLine("Train---------------");
var trainError = 0.0;
for (int epoch = 0; epoch++ < maxepoch;)
{
double error = 0;
// 随机取十分之一的训练数据进行训练
foreach (var data in train.Shuffle().Take(count))
{
// 前向传播计算输出
model.Forward(data.GetInput());
// 反向传播
model.Back(data.GetOutput(), lr);
// 累计误差
error += model.GetError(data.GetOutput());
}
trainError += error / count;
// 每10次输出一次误差
if (epoch % 10 == 0)
{
trainError = Math.Abs(trainError) / 10;
Console.WriteLine($"{epoch / 10}-epoch:{epoch}, error:{trainError}");
// 达到目标误差时停止训练
if (trainError < targetError)
break;
trainError = 0;
}
}
// 开始测试
Console.WriteLine("Test---------------");
var testError = 0.0;
foreach (var data in test)
{
// 前向传播计算输出
var output = model.Forward(data.GetInput());
// 输出真值和预测值进行对比
Console.WriteLine($"{data.GetOutput()[0].PadRight(10)}{output.First()}");
// 累计误差
testError += model.GetError(data.GetOutput());
}
// 输出平均测试误差
Console.WriteLine(testError / test.Count);
class StudentPreference
{
/// <summary>
/// 每个学生学习的总小时数
/// </summary>
public double Hours { get; set; }
/// <summary>
/// 学生在以前的测试中获得的分数
/// </summary>
public double PreScores { get; set; }
/// <summary>
/// 学生是否参加课外活动(是或否)
/// </summary>
public double Ext { get; set; }
/// <summary>
/// 学生每天的平均睡眠小时数
/// </summary>
public double Sleep { get; set; }
/// <summary>
/// 学生练习的样题数量
/// </summary>
public double Papers { get; set; }
/// <summary>
/// 衡量每个学生的整体表现
/// </summary>
public double Score { get; set; }
public double[] GetInput()
{
return new double[] { Hours, PreScores, Ext, Sleep, Papers };
}
public double[] GetOutput()
{
return new double[] { Score };
}
}
public class Neuron
{
/// <summary>
/// 简单初始化神经元
/// </summary>
public Neuron(IActivationFunction actFun)
=> (Inputs, Outputs, ActivationFunction, Bias) = (new List<Synapse>(), new List<Synapse>(), actFun, NetWork.GetRandom());
/// <summary>
/// 值
/// </summary>
public double Value { get; set; }
/// <summary>
/// 激活函数
/// </summary>
public IActivationFunction ActivationFunction { get; private set; }
/// <summary>
/// 偏置
/// </summary>
public double Bias { get; set; }
/// <summary>
/// 梯度
/// </summary>
public double Gradient { get; set; }
public double GetValue()
{
if (Inputs.NotEmpty())
Value = ActivationFunction.Forward(Inputs.Sum(i => i.Weight * i.Input.GetValue()) + Bias);
return Value;
}
public double GetGradient(double? target = null)
{
// 最后一层直接计算
if (target.HasValue)
Gradient = GetError(target.Value) * ActivationFunction.Back(Value);
// 如果存在输出神经元, 该神经元的梯度为后一层的梯度加权求和乘以偏导
if (Outputs.NotEmpty())
Gradient = Outputs.Sum(i => i.Output.Gradient * i.Weight) * ActivationFunction.Back(Value);
// 如果存在输入神经元, 则计算前一层的梯度
if (Inputs.NotEmpty())
Inputs.ForEach(i => i.Input.GetGradient());
return Gradient;
}
public double GetError(double target) => target - Value;
/// <summary>
/// 更新权重
/// </summary>
/// <param name="lr"></param>
public void UpdateWeight(double lr)
{
// 计算权重变化量
var BiasDelta = lr * Gradient;
// 调整神经元的偏置
Bias += BiasDelta;
foreach (var synapse in Inputs)
// 更新突触权重
synapse.Weight += BiasDelta * synapse.Input.Value;
}
/// <summary>
/// 输入
/// </summary>
public List<Synapse> Inputs { get; set; }
/// <summary>
/// 输出
/// </summary>
public List<Synapse> Outputs { get; set; }
}
默认的权重更新算法可能会有点慢, 这个时候可以考虑加一点 动量(Momentum) 加快误差下降
public void UpdateWeight(double lr, double mont = 1)
{
// 计算权重变化量
var BiasDelta = lr * Gradient;
// 调整神经元的偏置
Bias += BiasDelta;
foreach (var synapse in Inputs)
{
// 更新突触权重
var preDelta = synapse.WeightDelta;
synapse.WeightDelta = BiasDelta * synapse.Input.Value;
// 使用上一次的变化量和动量加快收敛
synapse.Weight += synapse.WeightDelta + preDelta * mont;
}
}
public class Synapse
{
public Synapse(Neuron input, Neuron outPut)
{
(Input, Output, Weight) = (input, outPut, NetWork.GetRandom());
Input.Outputs.Add(this);
Output.Inputs.Add(this);
}
/// <summary>
/// 输入端
/// </summary>
public Neuron Input { get; set; }
/// <summary>
/// 输出端
/// </summary>
public Neuron Output { get; set; }
/// <summary>
/// 权重
/// </summary>
public double Weight { get; set; }
/// <summary>
/// 权重导数
/// </summary>
public double WeightDelta { get; set; }
}
public interface IActivationFunction
{
/// <summary>
/// 前向
/// </summary>
double Forward(double input);
/// <summary>
/// 反向
/// </summary>
double Back(double input);
}
public class ReLu : IActivationFunction
{
public double Forward(double input) => input > 0 ? input : 0;
public double Back(double input) => input >= 0 ? 1 : 0;
public static ReLu Instance = new ReLu();
}
public class Linear : IActivationFunction
{
public double Forward(double input) => input;
public double Back(double input) => input;
public static Linear Instance = new Linear();
}
public class Layer : IEnumerable<Neuron>
{
public IActivationFunction ActivationFunction { get; private set; }
public Layer(int size, IActivationFunction actFunc)
{
Neurons = new Neuron[size];
ActivationFunction = actFunc;
foreach (var i in Enumerable.Range(0, size))
Neurons[i] = new Neuron(ActivationFunction);
}
/// <summary>
/// 上一层
/// </summary>
public Layer? Previous
{
get => previous; set
{
previous = value;
// 自动创建突触连接两次神经元
if (previous != null)
Neurons.ForEach(n => previous.Neurons.ForEach(p => _ = new Synapse(p, n)));
}
}
private Layer? previous;
/// <summary>
/// 下一层
/// </summary>
public Layer? Next { get; set; }
/// <summary>
/// 本层的神经元
/// </summary>
public Neuron[] Neurons { get; private set; }
public IEnumerator<Neuron> GetEnumerator()
{
return ((IEnumerable<Neuron>)Neurons).GetEnumerator();
}
IEnumerator IEnumerable.GetEnumerator()
{
return Neurons.GetEnumerator();
}
}
public class NetWork
{
public static Random Rand = new();
public NetWork()
{
Layers = new();
}
public List<Layer> Layers { get; set; }
/// <summary>
/// 输入层
/// </summary>
public Layer Input => Layers.First();
/// <summary>
/// 输出层
/// </summary>
public Layer Output => Layers.Last();
/// <summary>
/// 添加一层网络
/// </summary>
/// <param name="size">神经元数量</param>
/// <param name="actFun">激活函数</param>
/// <returns></returns>
public NetWork AddLayer(int size, IActivationFunction actFun)
{
// 如果添加了第一层, 直接进行初始化即可
if (Layers.IsEmpty())
Layers.Add(new Layer(size, actFun));
// 如果是之后的层, 则需要将前后两次进行连接
else
{
var previous = Output;
Layers.Add(new Layer(size, actFun));
// 连接前后两次神经元
Output.Previous = previous;
previous.Next = Output;
}
return this;
}
public IEnumerable<double> Forward(double[] inputs)
{
Input.SelectWithIndex().ForEach(i => i.value.Value = inputs[i.index]);
return Output.Select(i => i.GetValue()).ToList();
}
public void Back(double[] target, double lr)
{
// 计算所有神经元的梯度, GetGradient 内部有递归处理
Output.SelectWithIndex().ForEach(kv => kv.value.GetGradient(target[kv.index]));
// 先将网络反过来
Layers.Reverse();
// 然后从后完全一层一层更新偏置和权重
Layers.ForEach(i => i.ForEach(ii => ii.UpdateWeight(lr)));
// 更新完成之后再度翻转, 使得网络恢复原状
Layers.Reverse();
}
public double GetError(double[] target) => Output.SelectWithIndex().Sum(i => i.value.GetError(target[i.index]));
/// <summary>
/// 使用统一的随机数生成, 便于通过种子固定
/// </summary>
/// <returns></returns>
public static double GetRandom() => Rand.NextDouble() / 10;
/// <summary>
/// 设置随机数种子
/// </summary>
/// <param name="seed"></param>
public void SetRandSeed(int seed) => Rand = new Random(seed);
}